
The recent breakthrough in Large Language Models (LLMs), such as chatGPT, and generative models, such as Stable Diffusion, can be tremendously valuable in supporting analysis and creative tasks. While powerful, such models can be difficult to use, especially for domain experts, such as qualitative researchers and visual artists, who are not experts in machine learning. This project will investigate using generative AI models to support artistic creation. The goal is to first understand the user needs, then design interactive visual interface, and finally making recommendations.
Generative image models allow the creation of images based on a text prompt. However, the generated images can be unpredictable and it can be difficult to find the right prompt that can produce the desired image (‘prompt engineering’). Essentially the users need to learn to describe their vision and idea in a way that is understandable by a generative model, which even the machine learning experts do not understand how it ‘thinks’. The result is a time-consuming trial-and-error process that can take hours or days with no guarantee of a satisfying result. In this project, we work with artists, such as film maker Richard Ramchurn, founder of AlbinoMosquito Production, to develop tools that support the different stages of artistic creation.
Better Understanding of Generative AI Models
For many artists Generative AI models, or AI/machine learning in general, are not easy to understand. It is difficult to fully take advantage of these models without understanding:
- What they can and cannot do;
- What types of tasks they are good at;
- How to control the output with prompts;
- …
It is possible to take a training course on Generative AI, but most users, artists included, probably prefer to finding out the answers to these through hand-on experience. Following this idea, we created the PrompTHis to help artists better understand the capability of generative AI models and how to control them.

The left panel is where user enters the prompt and the right panel shows how the prompts changes over time and the resulting images.
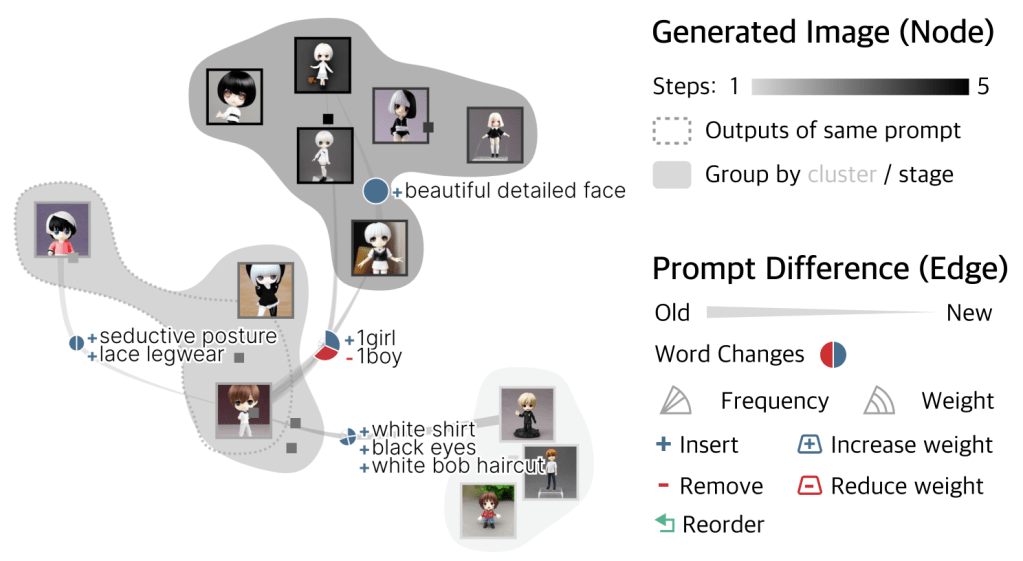
The middle panel groups all the generated images by either prompt text or image similarity (user can interactively change the weighting between the two). The links between the groups are labelled with the prompt text change between the two groups.
For more details, see the PrompTHis website or the paper (IEEE or arXiv).
Better management of the exploration process
Another common challenge when using generative models is that users may need to try dozens or more prompts before they can find something useful. Users can easily get lost in this process, forgetting what has been tried and what haven’t, or get stuck, not knowing how to further refine the prompt (after trying all the known options). Also, currently prompt history is commonly kept as a linear list, which does not reflect the thinking/exploration process, making it difficult to recall previous steps.

In the ongoing work of PrompMap, we are trying to address these challenges by
- Using a tree-like structure to better show the nature of the exploration/thinking process;
- Using the concept of ‘dimension’, i.e., an aspect of the prompt that user may experiment with different values (such as artistic style), to visualise the process in a more compact and organised way (the grid within the tree node);
- Automating the generation of image samples based on dimensions: for example, once user specified ‘artistic style’ as a dimension and listed a few interested styles, the tool can automatically generative images samples for each style;
- …
The work is still ongoing, and more updates will come soon.
Recommendations
The last stage of this project will be recommendation, i.e., recommend new prompts for users to try out. Currently, a popular approach is to curate a database of prompts and images, and recommend prompts that are similar (text wise) or result in similar images (image wise). While useful, this approach ignores the individual differences among users, as each user may have difference use case and/or preference.
We want to build a tool that can accommodate different user needs and preferences, adapting to different tasks at hand (even for the same user). This would require first learning the user task and preferences, which is a research problem of its own. This problem has been studied extensively in other fields, especially Information Retrieval, as search engines like Google or social media like Instagram are constantly trying to understand user preferences and recommend personalised contents.
The work on the recommendation has not started yet, and this will be a quite exciting research topic.
Readings
- Promptify: Text-to-Image Generation through Interactive Prompt Exploration with Large Language Models (UIST 2023) Video
- PromptMagician: Interactive Prompt Engineering for Text-to-Image Creation (TVCG 2023)
- Design Guidelines for Prompt Engineering Text-to-Image Generative Models (CHI 2022) video
- RePrompt: Automatic prompt editing to refine ai-generative art towards precise expressions (CHI2023) video
- PromptMaker: Prompt-based Prototyping with Large Language Models (CHI 2022)
- Dispensing with Humans in Human-Computer Interaction Research (CHI 2023)
- Designing Intelligent Tools for Creative People (IEEE CG&A 2023)

You must be logged in to post a comment.