
Key technologies:
Front end: React or Flutter.
Back end: vector database (chroma).
Machine learning: LLM, RAG (such as RAGFlow), agent orchestration framework (such as LangChain/LangGraph), and MCP.
You can see all the source code here.
Background
There are many types of qualitative analyses for academic publications. These are analyses that do not involve numerical computation (know as quantitative analysis). Literature review is probably the most common one that involves:
- Searching for relevant publications;
- Reading and understanding them, and
- Producing an overview or summary,
Examples include students preparing for their reports, scientist learning the research development, and product team understanding the current market landscape.
Traditionally literature review can be manual, laborious, and ineffective:
- Keyword search does not always work, as one idea can be expressed in may different ways, and it is difficult to compile a complete list of all possible keywords, which can introduce many irrelevant results.
- Reading and understanding papers are very time consuming: each paper can take from a few hours to several days, and some may require additional research and reading, e.g., to understand the concepts and/or methods mentioned.
- Producing a summary or overview usually require a lot of organisation (of the notes from paper reading) and thinking (e.g., categorising the existing work).
- For a popular field like AI, there can be hundreds or even thousands of potentially relevant publications and new ones appear constantly.
Progress – Vitality 2
To address these challenges we developed Vitality 2 (based on Vitality), a visual analytics tool to support literature review and analysis. Below is a video introducing the tool.
Its technical highlights include:
Semantic Relevance with LLM embedding
Large Language Models (LLMs) use text embedding to turn text into a vector. For example, chatGPT uses ADA embedding. Two semantically similar documents will be close to each other in this embedding space, even if they use very different words or phrase. This makes it an idea candidate for finding relevant documents, potentially producing much better results than keyword-based searches.
Similarity search with Vector Database
There is a new type of databased called vector database that can store documents in their vector form and find similar ones based on their distance in the embedding space. This makes it possible to take advantage of LLM embedding and search for similar documents in a very large collections.
Query through Chat
Large Language Models (LLMs) allow users to chat with their data without using any formal query language such as SQL. This makes it much easier for the users to get started. Also, the search or query can be very complex, as complex as natural language can describe, not limited by the syntax or constructure of any particular language.
Retrieval Augments Generation (RAG)
Prompt size limit
A year or two ago, most LLMs, such as chatGPT, has a limited prompt size (usually a few thousand tokens). This makes it not suitable for long documents such as academic papers, i.e., you cannot include an entire paper (usually more than 10k tokens) in the prompt if you want to ask a question about the paper, let alone questions about a collection of papers.
Information Relevance.
For tasks like literature review, users want answers or results based on the papers they are working on, not all the information on the internet, which is what most LLMs are trained. Also, LLMs usually do not have the most up-to-date information, unless it is constantly re-trained, which is very expensive. For example. GPT 3.5, which is used in chatGPT, has information up to September 2021.
Combining Database with LLM Generation
Retrieval Augments Generation (RAG) is the solution to these challenges. It uses traditional database query or information retrieval techniques to find relevant information from a given dataset, and include such information in the LLM prompt to generate better answers. If the information is over the prompt limit, the query results are summarised (usually using LLM) to reduce the size. The dataset can be easily updated to include the latest information, and this is much cheaper than re-training the LLM.
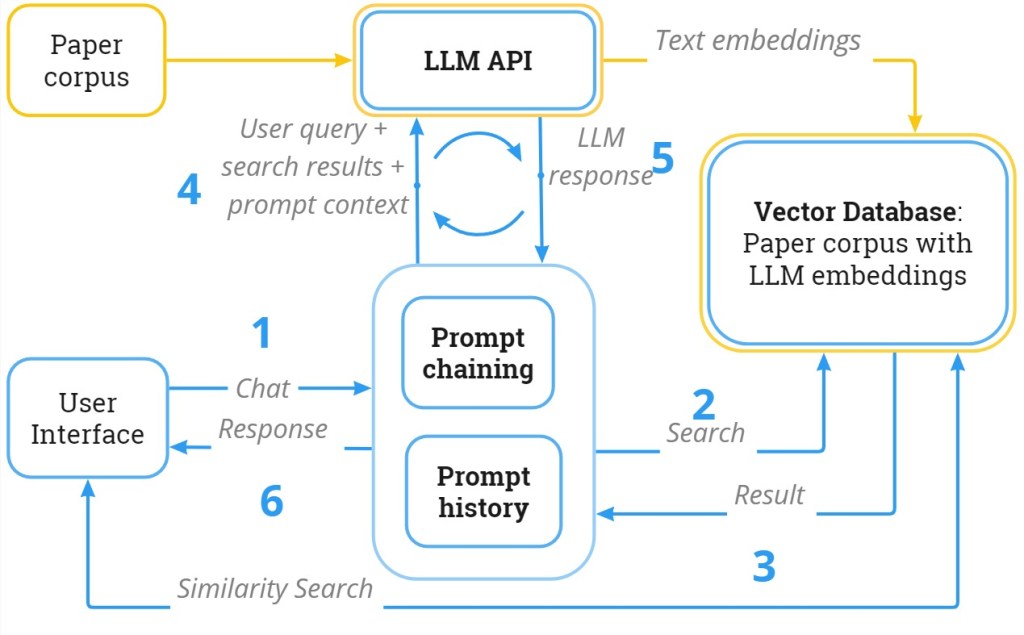
The system architecture
Below is Vitality2’s system architecture, and more details can be found in this paper.
Project ideas
So far most of the building blocks are completed and the next step is to better support different types of literature analyses such as literature review. This is where agentic analysis (using agent to automate some of the analysis) come into play.
Vitality 2 can’t quite do literature review yet. If you type in the prompt ‘write a literature review on LLM’, Vitality2 will return something but that is quite far from a proper literature review. There are a few reasons for this:
- Currently Vitality2 only searches for relevant paper in the RAG, but a literature review requires the most up-to-date publications, and this would require searching online database to find the latest work. Currently, Vitality2 get its paper information from Semantic Scholar API. By using MCP (model context protocol) an agent can automatically go to different online resource to find relevant papers.
- LLM would need much more detailed instructions than ‘write a literature review on LLM’ such as what are the different sections of a literature review, how to write each sections, and how to connect them together. This method is called chain-of-thoughts: breaking down a complex task into smaller ones, complete each individually, and combine the results. This usually requires a sophisticated agentic workflow, such as the ones used in the AI Scientist by sakana.ai.
- A user interface is needed to allow user control of the different parts of this agentic workflow. Otherwise, agents can easily get stuck and repeating the same attempts without making any progress.
- Ideally we want to allow users to add their own collection of paper and/or documents, as the default collection may not fully meet their needs. Such a collection can be an export from reference manager such as Zotero or Mendeley. This needs to be associated with individual users, as we don’t want an user to change the default Vitality collection or affect other users’ collecitons.
- Additionally, we want Vitality to periodically update its collection, e.g., after new papers are published from a conferences each year. It would be very interesting if we can notify users when new papers related to their interests are added, so they don’t need to go through hundreds or thousands papers to find relevant ones.
Readings
- vitaLITy 2: Reviewing Academic Literature Using Large Language Models (arXiv)
- VITALITY: Promoting Serendipitous Discovery of Academic Literature with Transformers & Visual Analytics (TVCG 2021, website with links to video, code, and dataset)
- Contextual retrieval to improve the retrieval part of the RAG (and BM25, a classical TF-IDF method).
- DocFlow: A Visual Analytics System for Question-based Document Retrieval and Categorization (VIS 2023, video)

You must be logged in to post a comment.